Botを入れれば質問対応が楽になると思っていた
映像制作工房LACでは、利用者さまの学習サポートにDiscordを使っています。利用者さまが学習中に出てきた疑問をチャットで送ると、サポーターが回答します。この流れ自体は問題なく機能していたのですが、サポーターの対応時間外に質問が溜まること、同じような質問が繰り返されることが気になっていました。
そこで、Q&Aチャットボットを導入しました。BotにメンションするとOpenAIのAssistants APIに質問が転送され、映像制作工房LACのカリキュラム情報をRAGで検索し、LLMが回答を生成して返します。24時間対応で、よくある質問ならBotが即答してくれます。サポーターの負担も減ります。そういう目論見でした。
で、実際に動かしてみたら、思っていたほど単純な話ではありませんでした。
映像制作工房LACとは
映像制作工房LACは、就労継続支援事業所様向けに、動画編集の学習カリキュラムを提供するサービスです。自社開発の学習管理システム上で利用者さまが動画講座の視聴や課題提出を進め、専門のサポーターがDiscordのテキストチャットで質問や相談に対応します。
ただし、目的は「動画編集ができる人」を育てることではありません。映像制作スキルの習得過程を通じて就労基礎動作を身につけ、就職につなげることが主な目的です。就職を目指さない方でも、事業所内で安定して活動できる人材になることを目指しています。
運用してみてわかった5つの課題
まず、チャンネルが会話で埋まりました。Botの回答がチャンネル本体に直接投稿されるので、質問と回答がずらっと並んで、サポーターからの連絡や運営のお知らせが流れてしまいます。Botが元気に働けば働くほどチャンネルが見づらくなるという、皮肉な状態でした。
次に、Botの回答で解決したのかしなかったのかがわかりません。利用者さまがBotの回答を読んで「なるほど」と思ったのか、「よくわからないけどまあいいか」と流したのか、結局サポーターに聞き直したのか。こちらからは全く見えません。Botの改善をしようにも、「何が答えられていないか」がわからないので手の打ちようがありません。
サポーターへの引き継ぎも曖昧でした。Botで解決しなかったとき、「サポーターに聞いてください」とテキストで案内するだけでした。サポーター側に通知が飛ぶわけでもないので、利用者さまは「サポーターに聞いてください」と言われたあと、どうすればいいかわからず止まってしまうことがありました。
メンション問題もありました。Botに質問するにはメンションが必要なのですが、メンションのやり方がわからない、忘れる、面倒。そういう理由でBotをスルーしてサポーターに直接聞く方が一定数います。Botがあるのに使われません。
そして、最も深刻だったのがLLMの嘘です。
Botが嘘をつく
ある日、利用者さまからPremiereのズームイン・ズームアウトのショートカットキーについて質問がありました。映像制作工房LACでは、カスタムショートカットとして「z」と「x」を設定しています。ところがBotは、一般的なデフォルトの「+」と「-」を案内してしまいました。
利用者さまからすると、教材には「zとx」と書いてあるのにBotは「+と-」と言っている。どっちが正しいのかわかりません。教材を信じればいいのか、Botを信じればいいのか。これは混乱します。
なぜこうなったか。RAGのナレッジベースにカスタムショートカットの情報が入っていなかったからです。ナレッジに該当する情報がないとき、LLMは自分の一般知識を使って回答を生成します。Premiereのデフォルトショートカットは「+」と「-」。LLMは嘘をついているつもりはなく、自分が知っている正しい情報を答えています。ただ、映像制作工房LACの環境では正しくありません。
プロンプトには「資料にない場合は資料にないと答えよ」と書いていました。でも、LLMにとっては「Premiereのショートカットは知っている」ので、「資料にない」とは思いません。プロンプトの指示と矛盾していないのです。これはプロンプトの書き方が悪いのではなく、LLMが「自分の知識」と「ナレッジベースの情報」を区別できないという構造の問題です。
ここで一つの判断をしました。適当に教えるくらいなら教えないほうがましです。利用者さまが混乱するリスクを取るくらいなら、「わかりません」と正直に言ったほうがいいと判断しました。

チャンネルの散らかりをスレッド化で解決
課題が5つ見えたので、優先度の高いものから順に手をつけていきました。
チャンネルが埋まる問題は、Botの回答をDiscordスレッドに切り出すことで解決しました。利用者さまが質問すると、Botが「質問:○○」というタイトルでスレッドを自動作成し、回答も追加の質問もすべてスレッド内で完結します。チャンネル本体にはスレッドの見出しが並ぶだけなので、他の情報が流れなくなりました。
利用者さまにとっても、自分の質問と回答が一箇所にまとまるので振り返りやすくなっています。地味な変更ですが、効果は大きかったです。
「解決した」「サポーターに聞く」をボタンに変更
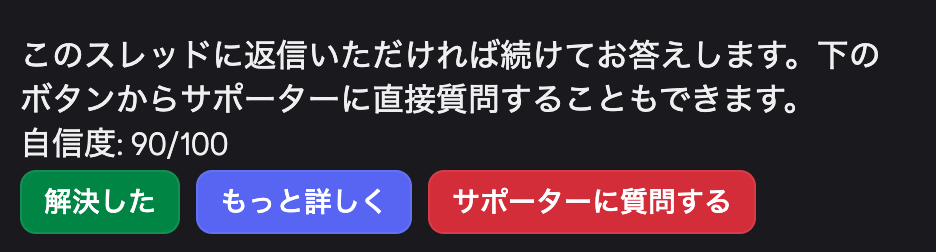
次に手をつけたのがボタンUIの導入です。Botが回答を返した後に「解決した」と「サポーターに質問する」の2つのボタンを表示するようにしました。
「解決した」を押せばスレッドがクローズされます。「サポーターに質問する」を押せば質問がサポーター用チャンネルに自動転送されます。テキストで「サポーターに聞いてください」と案内するだけだったのが、ボタン1つでサポーターにつながります。利用者さまにとっては「次にどうすればいいか」が明確になりました。
このボタン、利用者さま向けのUI改善として作ったのですが、副産物がありました。どちらのボタンが押されたかを記録すれば、「Botが答えられた質問」と「答えられなかった質問」が自動的に仕分けされるのです。このデータが溜まれば、ナレッジの拡充やRAGチューニングの優先度が判断できます。UIの改善が、そのまま改善材料の自動収集になっています。これは狙ってやったというより、作ってみたらそうなった、という面が正直あります。
サポーター側にもボタンを入れました。質問が転送されてきたときに「自分で対応する」と「運営にエスカレーション」の2つを表示します。「自分で対応する」を押すと対応者が明示されるので、複数のサポーターが同じ質問に重複対応するのを防げます。
サポーター側にもボタンを入れました。質問が転送されてきたときに「自分で対応する」と「運営にエスカレーション」の2つを表示します。「自分で対応する」を押すと対応者が明示されるので、複数のサポーターが同じ質問に重複対応するのを防げます。
メンションできない人をどうするか
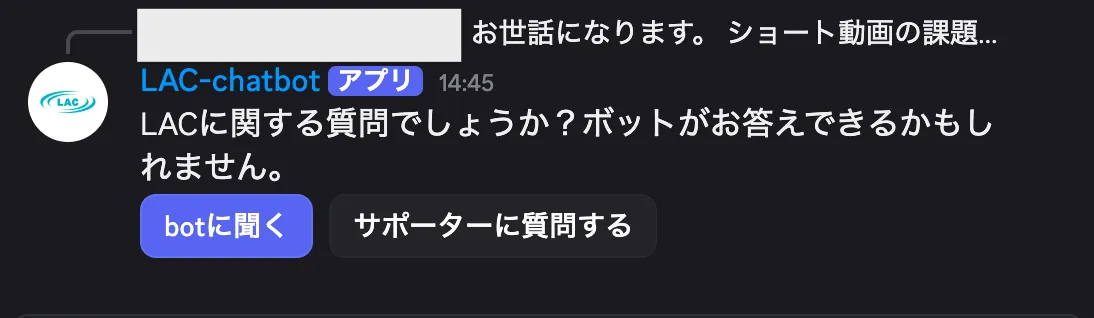
メンション問題は、正直悩みました。メンション必須をやめてすべての投稿にBotが反応するようにすると、雑談や挨拶にまでBotが出てきてうっとうしい。かといってメンション必須のままだと、メンションできない人はBotを使えない。
結局、間をとる形にしました。メンションなしの投稿に対しては、まずスクリプトで明らかなノイズを弾きます。5文字未満の短文、「おはようございます」のような定型挨拶、スタンプや画像のみの投稿、サポーターや運営メンバーの投稿。サポーターが利用者さまに回答しているところにBotが割り込んできたら最悪なので、ここは慎重にフィルタリングしました。
スクリプトを通過したメッセージは、軽量なLLMに渡して「これは質問かどうか」を判定させています。質問だと判定されたら、いきなり回答を返すのではなく「botに聞く」「サポーターに質問する」のボタンを提示する。メンション付きならBotが即座に回答、メンションなしならスクリプト→LLM判定→選択肢提示、という流れです。
GigafileのURLを拾って納品通知を自動化
映像制作工房LACの講座の一部に、「納品」の課題があります。これは案件を見据えてGigafileを使ってやり取りします。以前は動画をアップロードした後に「提出しました」とサポーターに別途連絡する必要がありました。この「別途連絡」を忘れる方がいて、サポーター側も納品に気づかないことがあった。
そこで、監視対象のチャンネルでGigafileのURLが投稿されると、Botが「納品の課題の提出ですか?」と確認ボタンを出すようにしました。「はい」を押すとサポーター用チャンネルに自動通知が飛ぶ。サポーター側には「対応する」ボタンが表示され、対応開始を宣言できます。
報告と確認のやりとりが仕組みで回るようになったので、「提出したのに気づいてもらえなかった」「連絡を忘れた」がなくなりました。

LLMの嘘をどう止めるか
さて、最も厄介だったLLMの嘘問題です。
最初に試したのはプロンプトの強化です。「自分の知識で補完するな」「ナレッジに該当する情報がない場合はその旨を回答せよ」と明記しました。効果はゼロではなかったものの、根本的な解決にはなりませんでした。LLMは「自分は知っている」と判断しているので、「知識で補完するな」という指示と「自分が知っていることを答える」という行動が矛盾しない。これはプロンプトをどう書いても回避しきれない問題です。
そこで、発想を変えました。LLMに「答えるな」と指示するのではなく、そもそもLLMに回答を生成させないようにする。判断をLLMの外に出す、ということです。
さて、最も厄介だったLLMの嘘問題です。
最初に試したのはプロンプトの強化です。「自分の知識で補完するな」「ナレッジに該当する情報がない場合はその旨を回答せよ」と明記しました。効果はゼロではなかったものの、根本的な解決にはなりませんでした。LLMは「自分は知っている」と判断しているので、「知識で補完するな」という指示と「自分が知っていることを答える」という行動が矛盾しません。これはプロンプトをどう書いても回避しきれない問題です。
そこで、発想を変えました。LLMに「答えるな」と指示するのではなく、そもそもLLMに回答を生成させないようにします。判断をLLMの外に出す、ということです。
スコア判定をコード側でやる
具体的にやったことはこうです。利用者さまが質問を送ると、まずナレッジベースに対して類似度検索が走ります。このとき、検索結果にはスコアが付いています。「質問とナレッジの内容がどれくらい近いか」を数値で示すものです。
従来は、このスコアに関係なく検索結果をLLMに渡して回答を生成させていました。改修後は、スコアをコード側で判定します。スコアが閾値以上なら、ナレッジに十分な情報があると判断してLLMに回答を生成させます。スコアが閾値未満なら、LLMを経由せずに利用者さまに選択肢を出します。「一般的な情報を調査する」と「サポーターに質問する」の2つです。
「一般的な情報を調査する」を利用者さまが自分で選んだ場合のみ、LLMの一般知識で回答します。ただし「これは映像制作工房LAC固有の情報ではなく、一般的な情報です」と注記が付きます。利用者さまは「公式の回答ではない」と認識した上で情報を受け取ることになります。
ポイントは、「答えるかどうか」の判断をLLMにさせていないことです。スコアが閾値を超えているかどうかは、コードが数値を比較するだけです。LLMの曖昧な判断が入り込む余地がありません。プロンプトでお願いしてもダメだったことが、コード数行で解決しました。LLMを信頼しすぎない、というのは今回の改修で一番大きな学びでした。
回答ルールも見直した
個別の改修とあわせて、Botの回答ルール全体も手を入れました。
もともとLLMは長い回答をダラダラ返す癖がありました。プロンプトで文字数を制限しても守りません。そこで構造自体を変えて、まず回答の要約だけを返し、利用者さまが詳細を求めたときにはじめて長い回答を出す形にしました。要約で済む質問はそこで完結しますし、足りなければ掘り下げられます。プロンプトで抑えつけるより、仕組みで制御したほうが確実でした。
自信度が低いときの案内文も変えました。「講師・サポーターからの補足をお待ちください」だと、利用者さまは待つしかありません。「サポーターへの質問もお試しください」に変えて、利用者さま自身が次のアクションを取れるようにしました。小さい変更ですが、「待つ」と「動ける」の差は大きいです。
情報が不足しているときは、以前はそのまま不完全な回答を返していましたが、まず回答を試みたうえで「この点についてもう少し詳しく教えていただけると正確に回答できます」と聞き返すようにしました。回答末尾にも「スレッド返信で追加質問できます」「ボタンからサポーターに質問できます」と案内を入れて、Botの回答を見た後に迷子にならないようにしています。
データを自動で溜める仕組みを入れた
ここまでの改修を支える基盤として、Botが処理した質問をGoogle Sheetsに自動記録するようにしました。日時、質問内容、Botの回答、ステータス、検知方式、応答時間。手動でログを取るのは続かないので、全部自動です。
あわせて、日次レポートを毎日18時に管理チャンネルへ自動投稿するようにしました。質問件数、解決率、検知方式の内訳、平均応答時間、未応答数が一目でわかります。Botがちゃんと仕事をしているか、日単位で追えます。
サポーター向けには、毎日11時と14時に対応待ちの質問一覧を自動投稿しています。出勤してきたときに「今日はこれだけ溜まっている」がすぐ見えます。急ぎで確認したいときは /queue コマンドで手動取得もできます。
振り返ってみて思うこと
改修前のBotは「質問すれば答えてくれる箱」でした。改修後は「答えられることは答える、答えられないことは正直にそう言う、どちらにしても次のアクションを示す」という振る舞いに変わっています。
利用者さまにとって一番変わったのは、「聞き方がわからない」「Botに嘘を教えられた」「その後どうすればいいかわからない」という3つの詰まりポイントがなくなったことだと思います。メンションなし検知で質問のハードルが下がり、スコア制御で嘘がなくなり、ボタンで次のアクションが常に明確になりました。
サポーターにとっては、対応の重複が防げるようになったことと、Botが答えられなかった質問がデータとして見えるようになったことが大きいです。ナレッジの拡充も「なんとなく足りない気がする」ではなく「この質問でサポーターに転送されている」という事実から優先度をつけられるようになりました。
LLMを信頼しすぎない、という設計判断
今回の改修で一番考えさせられたのは、LLMとの距離感の話です。
LLMは賢いです。大抵のことはうまく答えてくれます。でも、「自分の知識」と「外部のナレッジ」の境界を正確に引くことは、今のLLMには難しいです。プロンプトでどれだけ丁寧にお願いしても、ここは構造的に超えられない壁があります。
だから、LLMに任せていい部分と、コードやルールで制御すべき部分を分ける必要があります。今回で言えば、「ナレッジの情報をもとに回答を組み立てる」のはLLMが得意な仕事です。一方で、「そもそもナレッジに十分な情報があるかどうか」を判断するのは、コードでスコアを比較したほうが確実です。
映像制作工房LACは就労支援の学習サービスです。利用者さまはカリキュラムを信頼して学んでいます。その信頼の上に乗っているBotが間違った情報を返すのは、単なる回答ミスではなく、学習そのものを壊しかねません。だから「適当に教えるくらいなら教えないほうがまし」なのです。この判断はたぶん、今後も変わりません。
終わりではなく、途中の記録
ナレッジの拡充はまだ道半ばです。映像制作工房LACのカリキュラムは更新されていくので、ナレッジも追従しないといけません。特に、一般的な情報と映像制作工房LAC固有の設定が違うポイントは、一つずつ潰していかなければなりません。
スコアの閾値も、今の設定が最適かどうかはまだわかりません。高すぎればBotが「わかりません」を連発して役に立たず、低すぎれば嘘のリスクが上がります。ボタンの押下データを分析して、「サポーターに転送されたけど実はBotが答えられたはずの質問」がどれくらいあるかを見ながら調整していく作業が残っています。
この記事に書いたことも、数ヶ月後には「あのときはこう考えていたけど、実際はこうだった」という話が出てくるかもしれません。そのときはまた書きます。
